本章节的代码在Mac上完成,Windows平台会有差异。
部署开发测试环境
有两种方式在本机安装开发测试环境:
-
pip install scrapy scrapy shell 使用Vagrant安装Learning Scrapy的Docker Images
git clone https://github.com/scalingexcellence/scrapybook.git cd scrapybook vagrant up --no-parallel
注意:在Mac上,如果没有本地安装docker,则需要修改Vagrant文件,设置d.force_host_vm = true。
开发爬虫代码
网络爬虫的处理流程:
- 指定起始URL
- 指定抓取URL
- 指定抓取Item
- 输出抓取Item
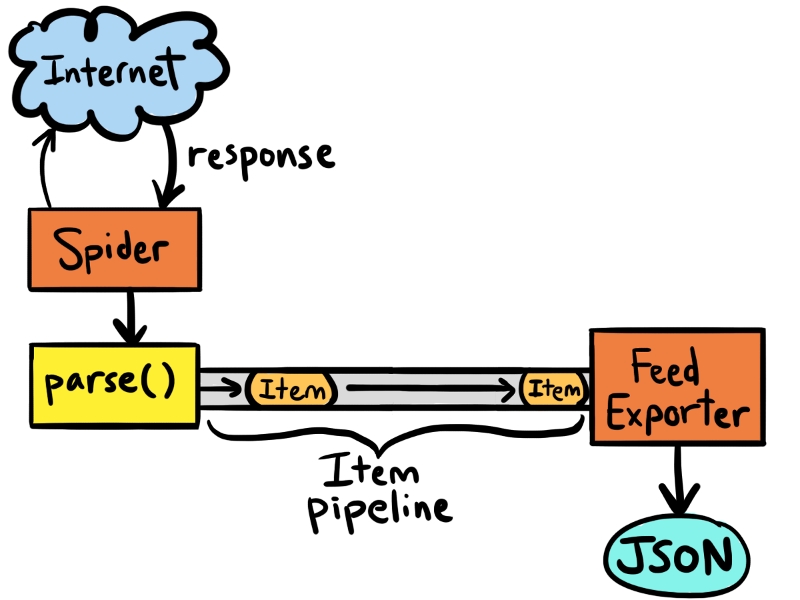
起始URL:
Yelp餐馆页面样例:
| 餐馆列表 | 餐馆信息 |
|---|---|
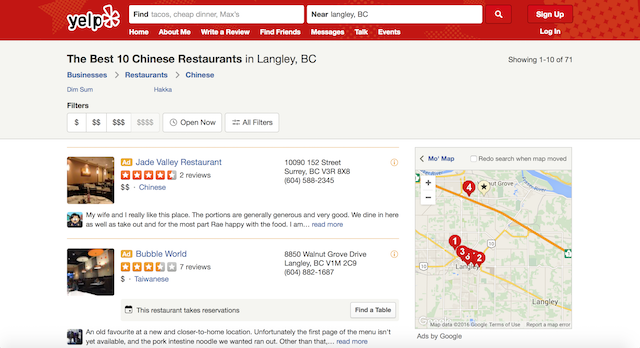 |
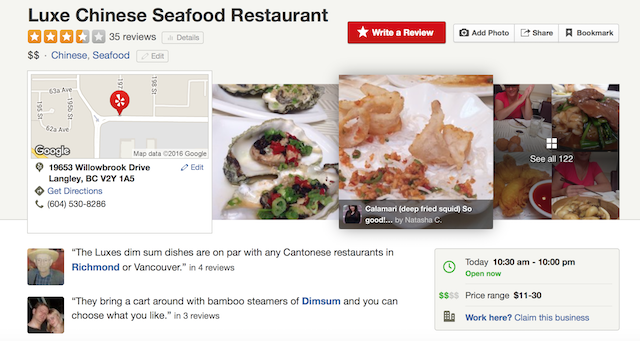 |
抓取项:
- 餐馆基本信息:名字,地址,电话
- 餐馆评价星级
- 餐馆评论信息
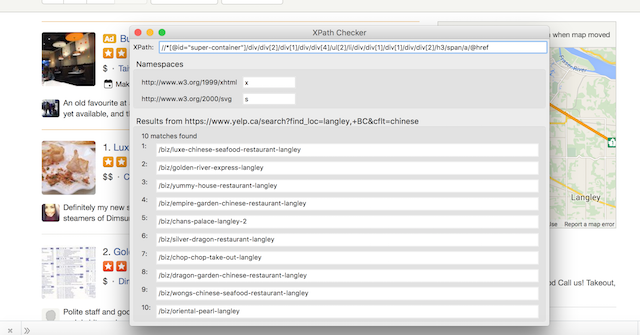
首先通过Chrome浏览器找到一个餐馆url的xpath:
//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href'
然后通过比较其他餐馆url在Firefox的xpath中验证得出通用的xpath:
//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href
(以后通过机器学习等方式可以做到自动化解析)
截屏演示:
| Step 1 | Step 2 | Step 3 | Step 4 |
|---|---|---|---|
 |
 |
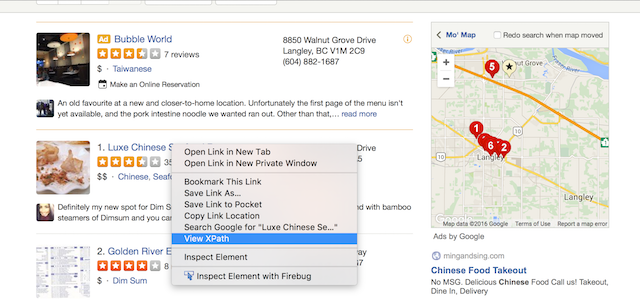 |
 |
最后得到抓取Yelp网站的第一个Spider:
import scrapy
class YelpSpider(scrapy.Spider):
name = 'yelpspider'
start_urls = ['https://www.yelp.ca/search?find_loc=langley,+BC&cflt=chinese']
def parse(self, response):
urls = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href').extract()
for url in urls:
yield {'url': response.urljoin(url)}
运行命令:
$ scrapy runspider YelpSpider.py -o urls.json
得到结果:
[
{"url": "https://www.yelp.ca/biz/luxe-chinese-seafood-restaurant-langley"},
{"url": "https://www.yelp.ca/biz/golden-river-express-langley"},
{"url": "https://www.yelp.ca/biz/yummy-house-restaurant-langley"},
{"url": "https://www.yelp.ca/biz/empire-garden-chinese-restaurant-langley"},
{"url": "https://www.yelp.ca/biz/chans-palace-langley-2"},
{"url": "https://www.yelp.ca/biz/silver-dragon-restaurant-langley"},
{"url": "https://www.yelp.ca/biz/chop-chop-take-out-langley"},
{"url": "https://www.yelp.ca/biz/dragon-garden-chinese-restaurant-langley"},
{"url": "https://www.yelp.ca/biz/wongs-chinese-seafood-restaurant-langley"},
{"url": "https://www.yelp.ca/biz/oriental-pearl-langley"}
]
我们需要把全部餐馆的链接抓取下来,因此按照上面的方法找出Next链接的xpath,递归抓取全部url:
import scrapy
class YelpSpider(scrapy.Spider):
name = 'yelpspider'
start_urls = ['https://www.yelp.ca/search?find_loc=langley,+BC&cflt=chinese']
def parse(self, response):
urls = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href').extract()
for url in urls:
yield {'url': response.urljoin(url)}
next_page = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/div/div/div/div[2]/div/div[last()]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
输出文件:urls.json
取得全部的餐馆url后,我们需要对每个餐馆页面进行解析,获取我们需要的分析数据。首先分析餐馆的基本信息的xpath:
餐馆名字 name:
//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[1]/h1/text()
餐馆地址 address:
//*[@id="wrap"]/div[3]/div/div[1]/div/div[3]/div[1]/div/div[2]/ul/li[1]/div/strong/address//text()
餐馆电话 phone:
//*[@id="wrap"]/div[3]/div/div[1]/div/div[3]/div[1]/div/div[2]/ul/li[3]/span[3]/text()
评价数量 review_counts:
//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[2]/div[1]/div[1]/span/span/text()
评价星级 review_stars:
//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[2]/div[1]/div[1]/div/meta/content/text()
代码如下:
import scrapy
class YelpSpider(scrapy.Spider):
name = 'yelpspider'
start_urls = ['https://www.yelp.ca/search?find_loc=langley,+BC&cflt=chinese']
def parse(self, response):
urls = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href').extract()
for url in urls:
yield scrapy.Request(response.urljoin(url), callback=self.parse_contents)
# yield {'url': response.urljoin(url)}
next_page = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/div/div/div/div[2]/div/div[last()]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
def parse_contents(self, response):
name = ' '.join(response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[1]/h1/text()').extract()).strip('n')
address = ' '.join(response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[3]/div[1]/div/div[2]/ul/li[1]/div/strong/address//text()').extract()).strip('n')
phone = ' '.join(response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[3]/div[1]/div/div[2]/ul/li[3]/span[3]/text()').extract()).strip('n')
review_counts = response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[2]/div[1]/div[1]/span/span/text()').extract()
review_stars = response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[2]/div[1]/div[1]/div/meta/@content').extract()
yield {'name': name,
'address': address,
'phone': phone,
'ranking':'',
'review_counts': review_counts,
'review_stars': review_stars,
'url': response.url
}
运行命令:
scrapy runspider YelpSpider.py -o restaurants.json
输出文件:restaurants.json
关于xpath的学习,请参考w3schools XPath Syntax
评论抓取
评论一般是网页中很难抓取的部分,因为这部分经常是动态生成,通过常规方式得到的xpath和实际的网页源代码对应不上,这时就需要通过scrapy shell进行调试分析了。
通过Chrome进行网页分析,得出下面的xpath:
餐馆网页 restaurant url:
https://www.yelp.ca/biz/luxe-chinese-seafood-restaurant-langley
餐馆评论部分 reviews_section:
//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li
评论用户名称 reviews_user:
//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li[2]/div/div[1]/div/div/div[2]/ul[1]/li[1]/a/text()
评论用户链接 reviews_user_url:
//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li[2]/div/div[1]/div/div/div[2]/ul[1]/li[1]/a/@href
评论日期 reviews_date:
//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li[2]/div/div[2]/div[1]/div/span/meta/@content
评论星级 reviews_stars:
//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li[2]/div/div[2]/div[1]/div/div/div/meta/@content
评论内容 reviews_content:
//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li[2]/div/div[2]/div[1]/p
得到代码:
import scrapy
class YelpSpider(scrapy.Spider):
name = 'yelpspider'
start_urls = ['https://www.yelp.ca/search?find_loc=langley,+BC&cflt=chinese']
def parse(self, response):
urls = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href').extract()
for url in urls:
yield scrapy.Request(response.urljoin(url), callback=self.parse_contents)
next_page = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/div/div/div/div[2]/div/div[last()]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
def parse_contents(self, response):
name = ' '.join(
response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[1]/h1/text()').extract()).strip(
'n')
filename = 'temp_' + ''.join(name.split()) + '.html'
with open(filename, 'w') as f:
f.write(response.body)
reviews_sections = response.xpath('//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li')
for sel in reviews_sections:
reviews_user = sel.xpath('div/div[1]/div/div/div[2]/ul[1]/li[1]/a/text()').extract()
reviews_user_url = sel.xpath('div/div[1]/div/div/div[2]/ul[1]/li[1]/a/@href').extract()
reviews_date = sel.xpath('div/div[2]/div[1]/div/span/meta/@content').extract()
reviews_stars = sel.xpath('div/div[2]/div[1]/div/div/div/meta/@content').extract()
reviews_contents = sel.xpath('div/div[2]/div[1]/p/text()').extract()
yield {'name': name,
'reviews_user': reviews_user,
'reviews_user_url': response.urljoin(reviews_user_url),
'reviews_date': reviews_date,
'reviews_stars': reviews_stars,
'reviews_contents': reviews_contents,
'restaurant_url': response.url
}
运行命令:
scrapy runspider YelpSpider_Reviews.py -o restaurant_reviews.json
输出文件中只有部分信息。用scrapy shell进行测试的结果为空值:
>>> response.xpath('//*[@id="super-container"]/div/div/div[1]/div[3]/div[1]/div[2]/ul/li')
[]
为了便于调试,代码中已将获取网页保存至本地硬盘,用Chrome打开temp_LuxeChineseSeafoodRestaurant.html,找出这里的xpath:
//*[@id="super-container"]/div[1]/div/div[1]/div[4]/div[1]/div[2]
在scrapy shell中验证,结果如下:
>>> response.xpath('//*[@id="super-container"]/div[1]/div/div[1]/div[4]/div[1]/div[2]')
[<Selector xpath='//*[@id="super-container"]/div[1]/div/div[1]/div[4]/div[1]/div[2]' data=u'<div class="review-list">n '>]
修改代码:
import scrapy
class YelpSpider(scrapy.Spider):
name = 'yelpspider'
start_urls = ['https://www.yelp.ca/search?find_loc=langley,+BC&cflt=chinese']
def parse(self, response):
urls = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href').extract()
for url in urls:
yield scrapy.Request(response.urljoin(url), callback=self.parse_contents)
next_page = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/div/div/div/div[2]/div/div[last()]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
def parse_contents(self, response):
name = ' '.join(
response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[1]/h1/text()').extract()).strip(
'n')
# filename = 'temp_' + ''.join(name.split()) + '.html'
# with open(filename, 'w') as f:
# f.write(response.body)
reviews_sections = response.xpath('//*[@id="super-container"]/div[1]/div/div[1]/div[4]/div[1]/div[2]/ul/li')
# from scrapy.shell import inspect_response
# inspect_response(response, self)
for sel in reviews_sections:
reviews_user = sel.xpath('div/div[1]/div/div/div[2]/ul[1]/li[1]/a/text()').extract()
reviews_user_url = sel.xpath('div/div[1]/div/div/div[2]/ul[1]/li[1]/a/@href').extract()
reviews_date = sel.xpath('div/div[2]/div[1]/div/span/meta/@content').extract()
reviews_stars = sel.xpath('div/div[2]/div[1]/div/div/div/meta/@content').extract()
reviews_contents = sel.xpath('div/div[2]/div[1]/p/text()').extract()
print(reviews_user)
print(reviews_contents)
yield {'name': name,
'reviews_user': reviews_user,
'reviews_user_url': 'https://www.yelp.ca' + ''.join(reviews_user_url),
'reviews_date': reviews_date,
'reviews_stars': reviews_stars,
'reviews_contents': reviews_contents,
'restaurant_url': response.url
}
评论中也涉及到翻页,代码如下:
import scrapy
class YelpSpider(scrapy.Spider):
name = 'yelpspider'
start_urls = ['https://www.yelp.ca/search?find_loc=langley,+BC&cflt=chinese']
def parse(self, response):
urls = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/ul[2]/li/div/div[1]/div[1]/div/div[2]/h3/span/a/@href').extract()
for url in urls:
yield scrapy.Request(response.urljoin(url), callback=self.parse_contents)
next_page = response.xpath('//*[@id="super-container"]/div/div[2]/div[1]/div/div[4]/div/div/div/div[2]/div/div[last()]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
def parse_contents(self, response):
name = ' '.join(
response.xpath('//*[@id="wrap"]/div[3]/div/div[1]/div/div[2]/div[1]/div[1]/h1/text()').extract()).strip(
'n')
# filename = 'temp_' + ''.join(name.split()) + '.html'
# with open(filename, 'w') as f:
# f.write(response.body)
reviews_sections = response.xpath('//*[@id="super-container"]/div[1]/div/div[1]/div[4]/div[1]/div[2]/ul/li')
# from scrapy.shell import inspect_response
# inspect_response(response, self)
for sel in reviews_sections:
reviews_user = sel.xpath('div/div[1]/div/div/div[2]/ul[1]/li[1]/a/text()').extract()
reviews_user_url = sel.xpath('div/div[1]/div/div/div[2]/ul[1]/li[1]/a/@href').extract()
reviews_date = sel.xpath('div/div[2]/div[1]/div/span/meta/@content').extract()
reviews_stars = sel.xpath('div/div[2]/div[1]/div/div/div/meta/@content').extract()
reviews_contents = sel.xpath('div/div[2]/div[1]/p/text()').extract()
yield {'name': name,
'reviews_user': reviews_user,
'reviews_user_url': 'https://www.yelp.ca' + ''.join(reviews_user_url),
'reviews_date': reviews_date,
'reviews_stars': reviews_stars,
'reviews_contents': reviews_contents,
'restaurant_url': response.url
}
# filename = 'temp_review_urls.txt'
# with open(filename, 'a') as f:
# f.writelines(response.url + 'n')
review_next_page = response.xpath('//*[@id="super-container"]/div[1]/div/div[1]/div[4]/div[1]/div[3]/div/div/div[2]/div/div[last()]/a/@href')
if review_next_page:
url = response.urljoin(review_next_page[0].extract())
# filename = 'temp_review_urls.txt'
# with open(filename, 'a') as f:
# f.writelines(url + 'n')
yield scrapy.Request(url, self.parse_contents)
评论抓取部分如果读者有更好建议,欢迎留言联系。
Learning Scrapy建议使用scrapy parse进行调试:
$ scrapy parse --spider=basic http://web:9312/properties/property_000001.
html
增量抓取
如果数据没有发生变化,每天进行全量抓取解析,会浪费许多计算和存储资源。因此,需要使用增量抓取的策略,提高效率:
- 判断区域是否有新增餐馆或关闭餐馆
- 判断餐馆基本信息是否有变化,例如地址、电话等
- 判断餐馆评论是否有新增信息
方案确定后,需要部署爬虫到云端,每日定期爬取内容。
以上还处于思考阶段,后面会继续补充完善。
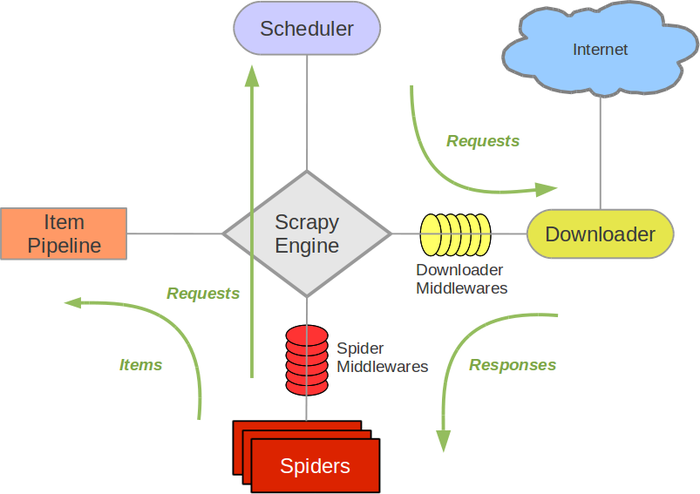
部署爬虫代码
爬虫代码可以在本地机器运行,也可以部署到云计算平台上。scrapy的架构在不做大改的情况下,单机较适合最多不超过千万级(每天千万的请求量,千万级的解析量(要看具体解析内容,解析是计算密集型))每天的爬取。 当你的爬虫效率低的时候,确认是卡在CPU、网络IO还是磁盘IO上。 卡在CPU上时,profile一下确认瓶颈代码段,scrapy自带的item_loader里面用了很多动态特性,较卡cpu。另外如果计算资源实在不够,只能在开发代码上优化一下,写出效率更高css、xpath选择器(少用通用选择器),但这样会影响开发效率。卡网络io时,测试下是自己网络不佳还是对面服务器扛不住了,也检查下dns。卡磁盘io时,看下数据库磁盘io。
部署到本地电脑
本机上安装好Scrapy后就可以直接运行命令抓取数据了。但是,很多网站会有反爬虫技术,经常会以封锁IP的方式停止返回请求,也会导致以后的正常请求不能使用。所以,在抓取数据时要注意不要过度,也可以通过设置代理等方式防止IP被封。
在运行Scrapy抓取命令前运行如下命令:
export http_proxy=http://proxy:port
部署到SaaS平台
shub login
Insert your Scrapinghub API Key: <API_KEY>
# Deploy the spider to Scrapy Cloud
shub deploy
# Schedule the spider for execution
shub schedule blogspider
Spider blogspider scheduled, watch it running here:
https://app.scrapinghub.com/p/26731/job/1/8
# Retrieve the scraped data
shub items 26731/1/8
{"title": "Black Friday, Cyber Monday: Are They Worth It?"}
{"title": "Tips for Creating a Cohesive Company Culture Remotely"}
...
在发布spider时需要用到Project ID,可以登录后在Spiders -> Codes & Deploys里找到:
The ID of the project:
73763
部署到IaaS平台
爬虫为计算密集型任务,IaaS的弹性资源调度这时可以帮忙。AWS EC2是一个很好的选择。可以参考文章:
How to crawl a quarter billion webpages in 40 hours
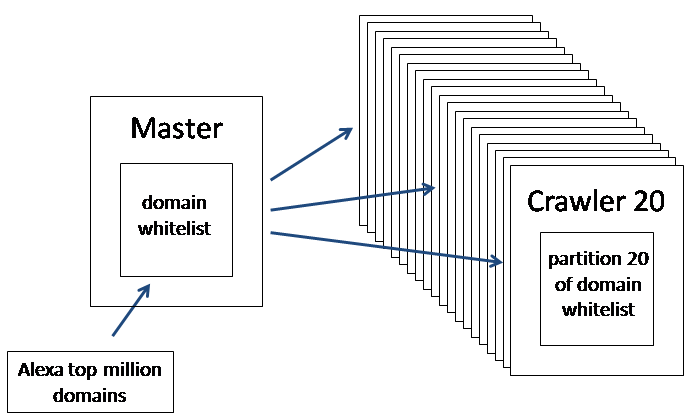
参考文章: 使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现, 爬虫状态显示使用graphite实现。