数据共享
目的
如果您需要更多支持和帮助,欢迎随时联系我们: contact@ascendtech.ca
介绍
数据共享可以有很多种形式:
- 原始文件:txt,json,csv,等等
- 固定报表:list, crosstab, 等等
- 即席查询:api,adhoc query, 等等
API
Amazon的Product Advertising API:

实现代码
import csv
import time
import json
from collections import OrderedDict
from datetime import datetime
from amazon.api import AmazonAPI
AMAZON_ACCESS_KEY = ''
AMAZON_SECRET_KEY = ''
AMAZON_ASSOC_TAG = ''
PRODUCT_ATTRIBUTES = [
'asin', 'author', 'binding', 'brand', 'browse_nodes', 'ean', 'edition',
'editorial_review', 'eisbn', 'features', 'get_parent', 'isbn', 'label',
'large_image_url', 'list_price', 'manufacturer', 'medium_image_url',
'model', 'mpn', 'offer_url', 'parent_asin', 'part_number',
'price_and_currency', 'publication_date', 'publisher', 'region',
'release_date', 'reviews', 'sku', 'small_image_url', 'tiny_image_url',
'title', 'upc'
]
amazon = AmazonAPI(AMAZON_ACCESS_KEY, AMAZON_SECRET_KEY, AMAZON_ASSOC_TAG)
global_node_options = ['link', 'image', 'text', 'script', 'link_text', 'style']
global_node_keys = ['asin', 'title', 'group', 'price', 'currency', 'offer_url', 'image_url']
def json_list(list_items, list_keys, list_name):
result = []
for item in list_items:
d = OrderedDict()
for i, list_key in enumerate(list_keys):
d[list_key] = item[i]
result.append(d)
# json_result = json.dumps(result, separators=(',', ':'))
d_result = OrderedDict()
d_result[list_name[0]]=list_name[1]
d_result['data'] = result
json_result = json.dumps(d_result, sort_keys=False)
return json_result
def get_result(search_keywords):
print(search_keywords)
# json_result: {api_provider: amazon.com, asin:, title:, group:, price:, currency:, offer_url:, image_url:}
results = list()
try:
products = amazon.search(Keywords=search_keywords, SearchIndex='All')
for product in products:
results.append([product.asin, product.title, product.get_attribute('ProductGroup'),
product.price_and_currency[0], product.price_and_currency[1],
product.offer_url, product.large_image_url])
except Exception as e:
print("error: %s".format(e))
json_result = json_list(results, global_node_keys, ['api_provider','amazon.com'])
return json_result
def save_result():
timestr = time.strftime("%Y%m%d-%H%M%S")
delimiter = ','
keywordFile = 'conf/search_keywords.csv'
outputFile = 'data/amazonItems' + timestr + '.csv'
logFile = 'logs/log' + timestr + '.csv'
failedKeywordsFile = 'logs/failedkeywords' + timestr + '.csv'
logFD = open(logFile, 'w+')
outputFD = open(outputFile, 'w+')
failedKeywordsFD = open(failedKeywordsFile, 'w+')
with open(keywordFile) as f:
reader = csv.reader(f)
f.readline()
count = 0
with open(outputFile, 'w+') as csvFile:
writer = csv.writer(csvFile, delimiter=';', quotechar='"', quoting=csv.QUOTE_ALL)
firstRow = ["product.asin", "product.title", "product.group", "product.price", "currency", "product.offer_url",
"product.large_image_url"]
writer.writerow(firstRow)
startTime = datetime.now().strftime("%Y%m%d-%H%M%S")
for row in reader:
keyword = row[0]
print(keyword)
count += 1
keywordStartTime = datetime.now().strftime("%Y%m%d-%H:%M:%S")
print("processing keyword {}: {} at {}".format(count, keyword, keywordStartTime))
logFD.write("processing keyword {}: {} at {} \n".format(count, keyword, keywordStartTime))
try:
products = amazon.search(Keywords=keyword, SearchIndex='All')
productCount = 0
for product in products:
try:
writer.writerow([product.asin, product.title, product.get_attribute('ProductGroup'),
product.price_and_currency[0], product.price_and_currency[1],
product.offer_url, product.large_image_url])
productCount += 1
except Exception as e:
print("error: %s".format(e))
logFD.write("error: %s \n".format(e))
continue
keywordEndTime = datetime.now().strftime("%Y%m%d-%H:%M:%S")
print("processed {} products of keyword: {} at {} ".format(productCount, keyword, keywordEndTime))
logFD.write(
"processed {} products of keyword: {} at {} \n".format(productCount, keyword,
keywordEndTime))
except Exception as e:
print("error: {}".format(e))
logFD.write("error: {} \n".format(e))
failedKeywordsFD.write("{}\n".format(keyword))
continue
time.sleep(2)
endTime = datetime.now().strftime("%Y%m%d-%H:%M:%S")
print("all complete at {}".format(endTime))
logFD.write("all complete at {}".format(endTime))
csvFile.close()
logFD.close()
outputFD.close()
failedKeywordsFD.close()
realtor.ca的API:
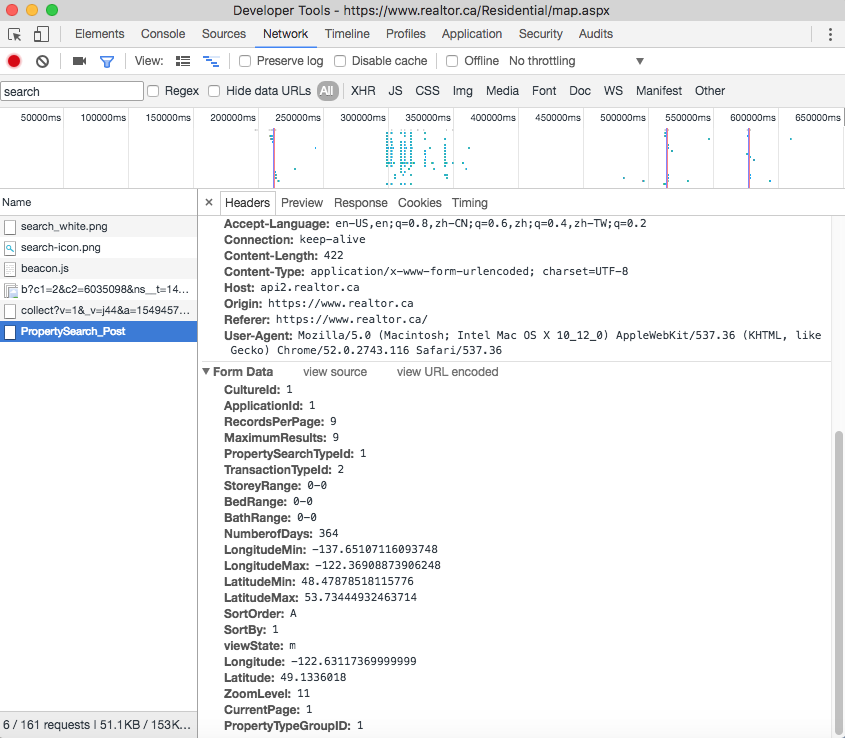
实现代码
# these two paras control listing result and amount for each post request
start_page = 1
records_paper_page = 200
number_of_days = 1
api_url = 'https://api2.realtor.ca/Listing.svc/PropertySearch_Post'
params = {
"CultureId": "1",
"ApplicationId": "1",
"RecordsPerPage": records_paper_page,
"MaximumResults": "9",
"PropertySearchTypeId": "1",
"TransactionTypeId": "2",
"StoreyRange": "0-0",
"BedRange": "0-0",
"BathRange": "0-0",
"NumberofDays": number_of_days,
"LongitudeMin": "-126.59401684296874",
"LongitudeMax": "-116.39870434296874",
"LatitudeMin": "48.1672551456224",
"LatitudeMax": "51.755325727529346",
"SortOrder": "A",
"SortBy": "1",
"viewState": "m",
"Longitude": "-122.64174005377839",
"Latitude": "49.14514549678261",
"ZoomLevel": "11",
"CurrentPage": start_page,
"PropertyTypeGroupID": "1"
}
# Adding header
headers = {
'Host': 'api2.realtor.ca',
'Accept': '*/*',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}
response = requests.post(url=api_url, data=params, headers=headers)
print response.content
json_response = json.loads(response.content)
print type(response.content)
houses = json_response['Results']
# print type(result)
print len(houses)
学习
实践
小结
如果您有数据分析咨询实施的需求,欢迎随时和我们联系!
email:contact@ascendtech.ca
微信扫码支持
| 友情支持 | 自由赞助 |
|---|---|
 |
 |